2026年4月2日,Google 正式推出了其最新一代开源模型家族 —— Gemma 4。这一代模型的核心理念在于:“不仅是更强的推理,更是更高效的执行。” 基于 Gemini 3 的同源技术,Gemma 4 在保持轻量化的同时,显著提升了每参数智能(Intelligence-per-parameter),为先进的推理和自主智能体(Agentic Workflows)提供了坚实的基础。

Gemma 4 不仅仅是一个简单的迭代,它在多个维度上重新定义了开源模型的标杆:
- Apache 2.0 协议:与前代部分限制不同,Gemma 4 全系列采用更开放的 Apache 2.0 许可,极大地方便了商业开发与集成。
- 256K 超长上下文:全系列模型支持高达 256K 的上下文窗口(E2B/E4B 为 128K),能够轻松处理长文档、复杂对话历史和大规模代码库。
- 原生多模态引擎 (Native Multimodality):Gemma 4 突破了纯文本的边界。全系模型均具备由底层训练得到的高阶视觉识别(Vision)能力,不仅能进行基础的图像描述,还能胜任复杂的图表结构解析(Chart Reasoning)、长文档 OCR 提取以及基于界面的 UI 分析。更具前瞻性的是,主打端侧计算的 E2B 和 E4B 模型集成了原生的音频理解(Audio Understanding)模块,能跨过传统的“语音转文字(STT)”中间步骤,直接“听懂”人类指令,大幅降低了语音助手的交互延迟。
- 智能体优先(Agentic First):原生支持智能函数调用(Function Calling)和结构化输出,专为构建能够执行复杂任务的 AI Agents 优化。
Gemma 4 提供了四种规格,以满足从端侧移动设备到高性能工作站的不同需求:
| 模型型号 | 架构类型 | 参数量 | 活跃参数 | 特点与应用场景 |
|---|
| Gemma 4 E2B | Dense | 2B | 2B | 为移动设备和边缘计算极致优化,支持音频输入。 |
| Gemma 4 E4B | Dense | 4B | 4B | 笔记本电脑端的理想选择,平衡了性能与资源消耗。 |
| Gemma 4 26B MoE | MoE | 26B | 4B | 使用 8 专家架构,高吞吐、低延迟,适合高性能 Web 服务。 |
| Gemma 4 31B Dense | Dense | 31B | 31B | 家族中的“六边形战士”,性能直逼前沿闭源大模型。 |
特别值得关注的是 26B MoE 模型。它虽然拥有 26B 的总参数量,但在推理时仅激活其中的 4B 参数。这意味着它能提供接近 31B 级别的知识储备,而推理速度却快如 4B 模型,是目前在大规模部署场景下的性价比王者。
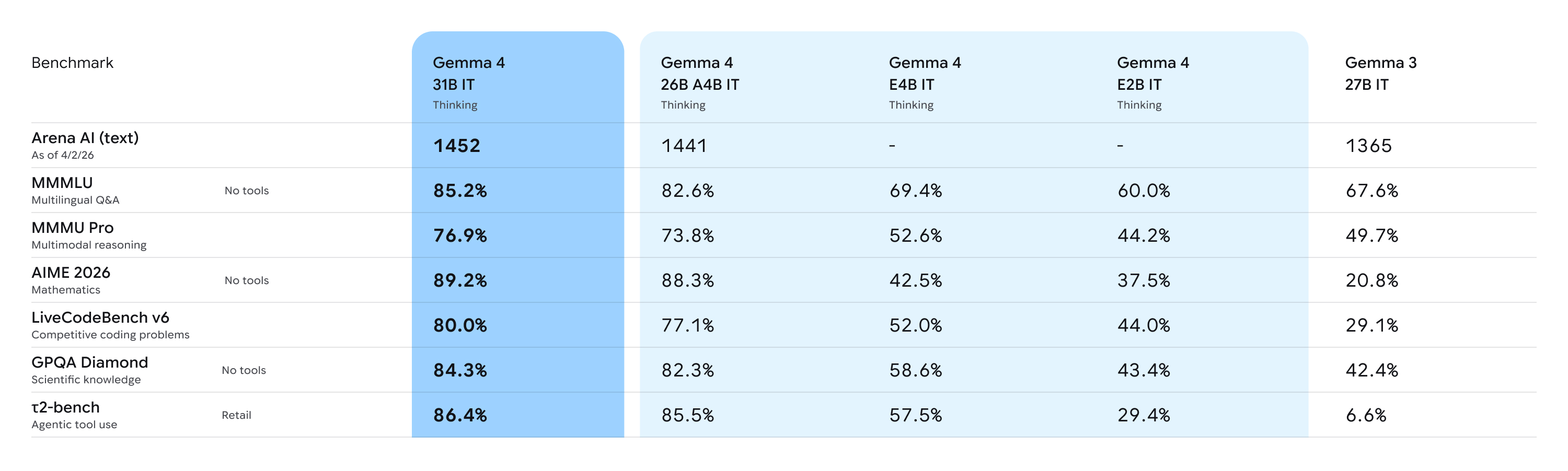
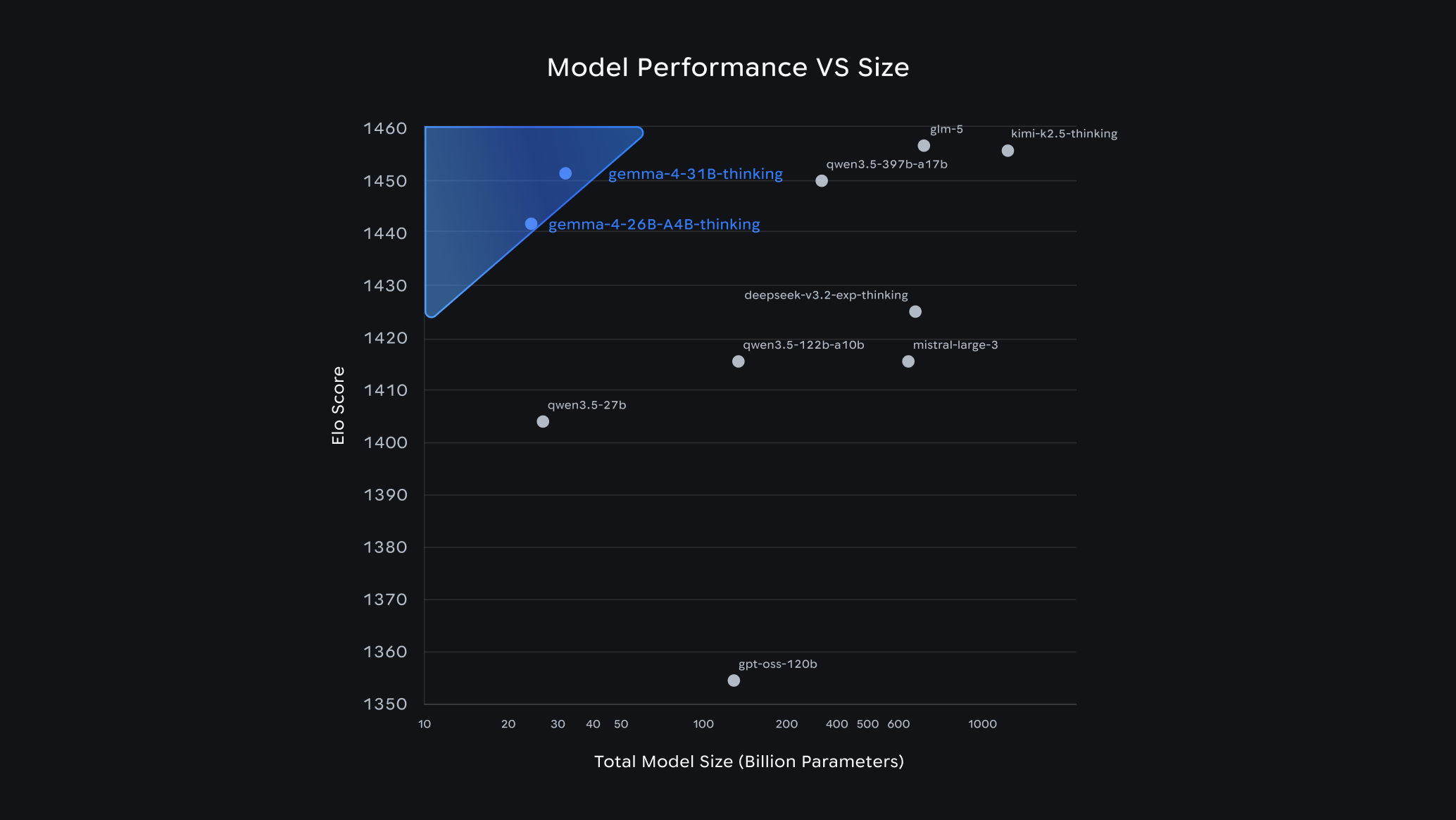
在 Arena.ai 的真实用户测评和多项 Benchmark 中,Gemma 4 展示了极其强悍的竞争力。尤其是 31B Dense 版本,在编程(Coding)和数学推理(Math Reasoning)方面甚至超越了参数量更大的同类竞争对手。
在介绍如何运行 Gemma 4 之前,我们需要先了解一下 Ollama。
Ollama 是一个专为本地运行大型语言模型(LLM)而设计的开源平台。你可以把它理解为“大模型的 Docker”。在过去,本地部署开源模型需要配置复杂的 Python 环境、安装 PyTorch、处理 CUDA 驱动,并手动编写推理代码。而 Ollama 将这些复杂的基础设施全部封装了起来。
Ollama 的核心优势包括:
- 开箱即用:无需复杂的环境配置,一条命令即可下载并启动模型,极其适合没有极客背景的普通开发者。
- 资源优化:底层基于
llama.cpp 构建,经过了深度的性能调优,支持各种量化格式(如 4-bit, 8-bit),能在内存和显存有限的消费级硬件(如普通的 Mac 或 Windows 游戏本)上高效运行。
- 兼容性极佳:自带类似于 OpenAI 的 RESTful API 接口,可以零成本对接到各种前端 UI(如 Chatbox, Open WebUI)或开发框架(如 LangChain, LlamaIndex)。
- 模型库极其丰富:官方维护的模型库更新极快,像 Gemma 4 这种前沿模型通常在发布当天就能在 Ollama 上体验。
如果你想在本地安全、隐私地测试 Gemma 4,同时又不想被环境配置所困扰,Ollama 是目前最优且门槛最低的选择。
接下来,我们将手把手教你如何通过 Ollama 在本地启动并驾驭 Gemma 4。
首先,前往 Ollama 官网 下载适用于你操作系统的安装包(全面支持 macOS, Windows 和 Linux)。
对于 macOS/Linux 极客用户,直接使用终端命令一键安装可能会更快:
curl -fsSL https://ollama.com/install.sh | sh
(🚨 提示:如果你以前安装过 Ollama,请务必执行上述命令或在软件内检查更新,以确保系统底层支持最新的 Gemma 4 模型结构。)
安装完成后,打开终端(Windows 环境下打开 PowerShell 或命令提示符)。根据你的硬件配置,选择合适的型号运行。这里我们回顾一下 Gemma 4 的几种规格匹配的机器要求:
ollama run gemma4
ollama run gemma4:e2b
ollama run gemma4:26b
ollama run gemma4:31b
当你输入指令后,Ollama 会自动从云端下载模型权重(根据网速可能需要几分钟)。下载完毕并加载进内存后,你会看到一个 >>> 持续等待的提示符,此时就已经进入了交互模式,可以直接在终端里和 Gemma 4 畅聊了!
由于 Gemma 4 全系支持多模态特征,在 Ollama 最新的终端界面中,你可以直接输入本地图片的绝对路径,让模型进行跨模态推理:
>>> 请仔细观察这张图片,详细描述图中右下角的细节内容:/Users/rainy/Downloads/test_image.jpg
(Ollama 会自动在后台读取、解析图片特征,并与文本一并输入给大模型,整个过程对用户是透明的)
作为一名开发者,单纯在终端里聊天显然是不够的。Ollama 启动后,默认会在系统的后台开启一个 HTTP API 服务(通常运行在 http://localhost:11434)。你可以直接通过标准 HTTP 请求与模型互动,这也意味着你可以无缝地将 Gemma 4 接入到你自己的代码逻辑中:
curl http://localhost:11434/api/generate -d '{
"model": "gemma4:26b",
"prompt": "请用 TypeScript 写一个并发任务队列的类,并添加详细的使用说明。",
"stream": false
}'
这就好比你在本地服务器上拥有了一个私有化、全免费、无 API 频率限制的大脑节点,你可以毫无顾忌地将它作为后端引擎,驱动你自己的“自主智能体(Autonomous Agents)”工作流。
终端虽好,但效率并非最高。Ollama 最具杀伤力的特性在于其极佳的生态兼容性:它不仅提供原生 API,还提供了完全兼容 OpenAI 协议的接口 /v1/chat/completions。这意味着绝大多数主流的 AI 生产力工具都可以一键接入本地的 Gemma 4。
以下是几种常见的接入姿势:
- Open WebUI:如果你想要一个完全本地化、体验堪比官方 ChatGPT 的可视化界面,Open WebUI 是最好的选择。它甚至支持本地知识库(RAG)、角色扮演和多模态图像识别,能够毫无障碍地调用你的本地
gemma4 实例。
- Chatbox:这是一款轻量级、跨平台的 AI 客户端。在设置中选择
Ollama API 模型提供商,API 地址填写 http://localhost:11434,即可在漂亮的 UI 中与 Gemma 4 对话。
- Continue.dev (IDE 插件):对于程序员而言,你可以将本地的 Gemma 4 变成免费的 Copilot。在 VS Code 或 JetBrains 中安装 Continue 插件,将其配置指向本地 Ollama,即可享受基于 Gemma 4 256K 超大上下文的代码补全、代码解释和重构建议。
- OpenCode:专为本地开源化定制的 IDE 辅助插件/编辑器环境,深度集成 Ollama 接口,可开箱即用地调用 Gemma 4 辅助完成端到端代码生成,完全保护代码资产隐私。
通过这一套组合拳(Gemma 4 (引擎) + Ollama (运行时) + WebUI / IDE 插件 (交互端)),你实质上在自己的电脑里搭建了一个完整的私有化 AI 工作站。
Gemma 4 的发布标志着 Google 在开源 AI 领域的承诺更进了一步。通过高密度的智能、开放的商业底座以及原生的多模态能力,它为开发者构建下一代“有感知、能思考、会执行”的 AI 智能体开启了巨大的想象空间。
结合像 Ollama 这样便捷优雅的基础设施,AI 大众化正以前所未有的速度推进。如果你正在物色 2026 年最核心的开发工具链,Gemma 4 与 Ollama 的组合绝对是不容错过的“趁手兵器”。


